🖥️ AI-LLM: Tencent en Tsinghua presenteren CALM - Voorbij next-token generatie
Tencent en Tsinghua University hebben gezamenlijk een nieuw onderzoeksartikel gepubliceerd dat het fundament van moderne taalmodellen radicaal heroverweegt. Zie rapport.
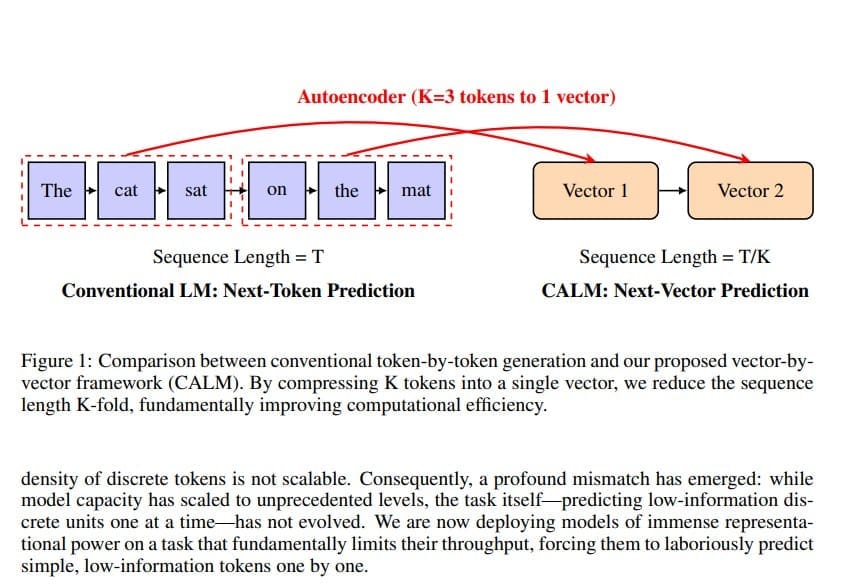
Zij lanceren CALM: een nieuw AI-model dat tekst voorspelt via continue vectoren in plaats van losse tokens. Dit verlaagt de rekenkosten met 30–45% zonder kwaliteitsverlies en markeert een fundamentele doorbraak in de efficiëntie en schaalbaarheid van taalmodellen.
In plaats van het traditionele principe waarbij elk volgend token afzonderlijk wordt voorspeld, stelt het paper een volledig nieuw paradigma voor: de Continuous Autoregressive Language Model-architectuur, kortweg CALM.
- CALM vervangt het token-voor-token mechanisme door het voorspellen van continue vectoren.
- Het model groepeert meerdere tokens in één enkele vector, wat het aantal generatie-stappen drastisch vermindert.
- Een geavanceerde autoencoder reconstrueert de oorspronkelijke tekst met meer dan 99,9 procent nauwkeurigheid.
- De nieuwe Energy Transformer maakt generatie zonder expliciete kansverdelingen mogelijk.
- Dit paradigma verlaagt de rekenkosten met 30 tot 45 procent, zonder prestatieverlies.
Het onderzoek richt zich op het doorbreken van de beperkingen van het token-voor-token systeem dat de kern vormt van vrijwel alle huidige large language models. Volgens de onderzoekers is dit mechanisme niet langer efficiënt genoeg voor verdere schaalvergroting.
Wil je alle artikelen kunnen lezen en elke podcast beluisteren? Neem dan een abonnement en krijg toegang tot alle artikelen en de database met duizenden berichten.
De reden is dat elk token gemiddeld slechts vijftien tot achttien bits aan informatie bevat, terwijl modellen met honderden miljarden parameters gedwongen blijven om deze minimale eenheden één voor één te voorspellen. CALM introduceert hiervoor een alternatief dat de efficiëntie van het gehele proces ingrijpend verbetert.
Van tokens naar vectoren
CALM werkt niet meer met discrete tokens, maar met continue vectoren. In plaats van één token per generatie-stap produceert het model een vector die meerdere tokens tegelijk omvat.
Een autoencoder leert om bijvoorbeeld vier tokens te comprimeren tot één enkele vector en die later met vrijwel perfecte nauwkeurigheid weer te reconstrueren.
In de experimenten behaalde het model een reconstructienauwkeurigheid van meer dan 99,9 procent. Hierdoor neemt het aantal benodigde generatie-stappen met een factor K af, waarbij K het aantal tokens per vector is.
Deze verschuiving betekent dat taal voortaan kan worden gemodelleerd als een reeks continue vectoren in plaats van een reeks discrete symbolen. Daardoor daalt het aantal berekeningen aanzienlijk, wat directe implicaties heeft voor snelheid, energieverbruik en schaalbaarheid.
De onderzoekers spreken van een verhoging van de semantische bandbreedte per stap – een nieuwe as van schaalvergroting die losstaat van het aantal parameters.
Een nieuw model zonder discrete uitkomsten
Omdat CALM niet langer werkt met discrete uitkomsten, is het onmogelijk om traditionele kansverdelingen of softmax-functies te gebruiken. Daarom ontwikkelden de onderzoekers een likelihood-vrij raamwerk dat taalmodellering volledig in de continue ruimte mogelijk maakt.
De kern van het systeem is de Energy Transformer, een generatief model dat in één stap een vector kan voorspellen in plaats van honderden iteraties te doorlopen zoals bij diffusie- of flowmodellen. Daarmee blijft de rekenkracht laag, terwijl de kwaliteit van de gegenereerde tekst hoog blijft.
Om het model te trainen en evalueren zonder traditionele waarschijnlijkheden, introduceert het team een nieuw metrisch systeem genaamd BrierLM. Deze metriek is gebaseerd op de Brier-score en maakt het mogelijk om modellen eerlijk te vergelijken op basis van hun output, ook wanneer de onderliggende kansverdeling onbekend is.
BrierLM bleek sterk te correleren met de klassieke cross-entropy-score, wat bevestigt dat het een betrouwbare vervanger is voor perplexity.
Efficiëntere generatie en temperatuurregeling
Een ander belangrijk onderdeel van CALM is de likelihood-vrije temperatuurregeling. In plaats van de gebruikelijke temperatuurinstelling via de softmax-logits, ontwikkelden de onderzoekers een nieuwe methode die volledig werkt met samples, zonder toegang tot de onderliggende kansverdeling.
Deze methode gebruikt een combinatie van herhalings- en batchsampling, gebaseerd op wiskundige principes uit de Bernoulli Factory-theorie. Hierdoor kan het model toch gecontroleerde variatie in de output genereren, iets wat essentieel is voor creativiteit en diversiteit in taal.
Resultaten en efficiëntie
De onderzoekers vergeleken CALM met standaard Transformer-modellen op benchmarks zoals WikiText-103. De resultaten tonen dat CALM met een chunkgrootte van vier tokens vergelijkbare prestaties behaalt als conventionele modellen, maar tegen 30 tot 45 procent lagere rekenkosten.
Bijvoorbeeld, het CALM-M model met 371 miljoen parameters evenaart de prestaties van een standaardmodel met 281 miljoen parameters, terwijl het 44 procent minder training-FLOPs en 34 procent minder inference-FLOPs vereist.
Bovendien schaalt CALM consistent met modelgrootte: grotere versies zoals CALM-XL blijven voordeel halen uit meer parameters, zonder dat de efficiëntiewinst verdwijnt.
De paper toont dat CALM in staat is om de traditionele prestatie-grens tussen modelgrootte en rekenkosten te doorbreken. In plaats van meer data of parameters te gebruiken, kan men voortaan ook de informatiecapaciteit per generatie-stap vergroten. Dit vormt volgens de auteurs een nieuwe en krachtige dimensie van schaalbaarheid voor toekomstige taalmodellen.
Implicaties voor de toekomst van taalmodellen
De introductie van CALM markeert een mogelijk keerpunt in de ontwikkeling van AI-modellen. Door de stap van discrete naar continue representaties kan de volgende generatie taalmodellen sneller, goedkoper en energiezuiniger worden getraind en ingezet.
Dit opent perspectieven voor toepassingen waar rekenkracht en latency cruciaal zijn, zoals real-time vertaling, spraakgestuurde interfaces en embedded AI-systemen.
Met deze publicatie lijkt Tencent, samen met Tsinghua University, een nieuw hoofdstuk in te luiden in de evolutie van taalmodellen. CALM is meer dan een technische optimalisatie: het is een fundamentele herziening van hoe taal zelf door machines wordt gemodelleerd.
Als deze aanpak verder wordt uitgewerkt en gecommercialiseerd, kan dit leiden tot een nieuwe generatie ultra-efficiënte AI-systemen die de beperkingen van het next-token paradigma definitief achter zich laten.
🔵 English version
Tencent and Tsinghua present Continuous Autoregressive Language Models (CALM): a fundamental shift beyond next-token prediction
Tencent and Tsinghua University have jointly published a new research paper that fundamentally rethinks the foundation of modern language models. Instead of the traditional principle where each next token is predicted individually, the paper introduces an entirely new paradigm: the Continuous Autoregressive Language Model architecture, or CALM.
- CALM replaces the token-by-token mechanism with continuous vector prediction.
- The model groups multiple tokens into a single vector, drastically reducing generation steps.
- A high-fidelity autoencoder reconstructs the original text with over 99.9 percent accuracy.
- The new Energy Transformer enables generation without explicit probability distributions.
- This paradigm lowers computational costs by 30 to 45 percent without sacrificing performance.
The research focuses on overcoming the inherent inefficiencies of the token-by-token system that underpins nearly all large language models. According to the authors, this mechanism is no longer sufficient for further scaling.
Each token carries only about fifteen to eighteen bits of information, yet today’s LLMs with hundreds of billions of parameters must predict these small units one by one. CALM introduces a new framework that dramatically improves the efficiency of the entire process.
From tokens to vectors
CALM no longer operates on discrete tokens but on continuous vectors. Instead of generating one token per step, the model produces a single vector representing several tokens at once.
An autoencoder learns to compress, for example, four tokens into one vector and later reconstruct them with near-perfect accuracy. In experiments, the reconstruction accuracy exceeded 99.9 percent. This reduces the number of generation steps by a factor K, where K equals the number of tokens per vector.
This transformation allows language to be modeled as a sequence of continuous vectors instead of discrete symbols. The result is a significant reduction in computation, with direct implications for speed, energy consumption, and scalability.
The researchers describe this as an increase in the semantic bandwidth per step – a new axis of scaling that exists independently from model size or parameter count.
A new model without probabilities
Because CALM operates in a continuous domain, it cannot rely on standard probability distributions or softmax layers. To address this, the researchers developed a likelihood-free framework that enables language modeling entirely in the continuous space.
At its core lies the Energy Transformer, a generative model capable of producing a single vector in one step, avoiding the hundreds of iterations used in diffusion or flow models. This keeps computational cost low while maintaining strong output quality.
To train and evaluate the model without conventional likelihoods, the team introduced a new metric called BrierLM. Based on the Brier score, it enables fair model comparison through output sampling alone, even when explicit probabilities are unavailable. BrierLM showed a strong correlation with traditional cross-entropy scores, confirming its reliability as a replacement for perplexity.
Efficient generation and temperature control
Another major contribution of CALM is its likelihood-free temperature control mechanism. Instead of using the traditional temperature adjustment through softmax logits, the researchers designed a new sampling method that relies entirely on model outputs, without any access to internal probability distributions.
The method combines repetition-based and batch-based sampling grounded in Bernoulli Factory mathematics, allowing CALM to maintain controlled variation in generated text – crucial for creative and diverse language generation.
Results and efficiency
The team benchmarked CALM against standard Transformer models on datasets such as WikiText-103. Results show that CALM, with a chunk size of four tokens, matches or exceeds baseline performance while cutting computation by 30 to 45 percent.
For instance, the CALM-M model with 371 million parameters achieves performance comparable to a 281-million-parameter Transformer while requiring 44 percent fewer training FLOPs and 34 percent fewer inference FLOPs. Moreover, CALM scales consistently with model size: larger models like CALM-XL retain these computational advantages as parameters increase.
The study demonstrates that CALM can break the traditional trade-off between model size and efficiency. Instead of scaling through sheer data and parameter count, it scales by increasing the information capacity per generative step. This establishes a new and powerful axis of scalability for future language models.
Implications for the future of language models
The introduction of CALM could mark a turning point in AI development. By transitioning from discrete tokens to continuous representations, the next generation of language models can be trained and deployed faster, cheaper, and with lower energy demands.
This shift has broad implications for applications where latency and efficiency are critical, including real-time translation, voice-driven interfaces, and embedded AI systems.
With this publication, Tencent and Tsinghua University appear to be opening a new chapter in the evolution of language models. CALM is more than a technical optimization; it represents a fundamental rethinking of how machines model human language.
If further developed and commercialized, this approach could lead to a new generation of ultra-efficient AI systems that finally leave the next-token paradigm behind.
Disclaimer Aan de door ons opgestelde informatie kan op geen enkele wijze rechten worden ontleend. Alle door ons verstrekte informatie en analyses zijn geheel vrijblijvend. Alle consequenties van het op welke wijze dan ook toepassen van de informatie blijven volledig voor uw eigen rekening.
Wij aanvaarden geen aansprakelijkheid voor de mogelijke gevolgen of schade die zouden kunnen voortvloeien uit het gebruik van de door ons gepubliceerde informatie. U bent zelf eindverantwoordelijk voor de beslissingen die u neemt met betrekking tot uw beleggingen.





